In the previous post we’ve seen the basics of Logistic Regression & Binary classification.
Now we’re going to see an example with python and TensorFlow.
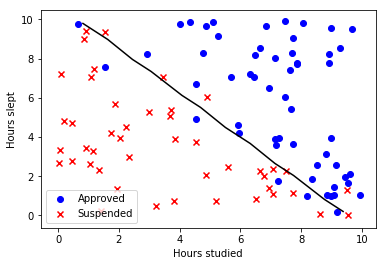
On this example we’re going to use the dataset that shows the probability of passing an exam by taking into account 2 features: hours studied vs hours slept.
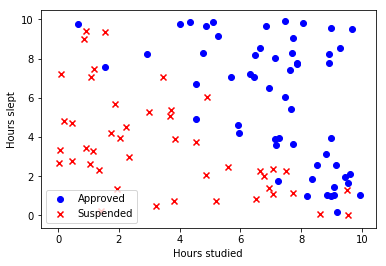
First, we’re going to import the dependencies:
1 | # Import dependencies |
1 | data = np.genfromtxt('data_classification.csv', delimiter=',') |
Now we’re building the logistic regression model with TensorFlow:
1 | learning_rate = 0.01 |
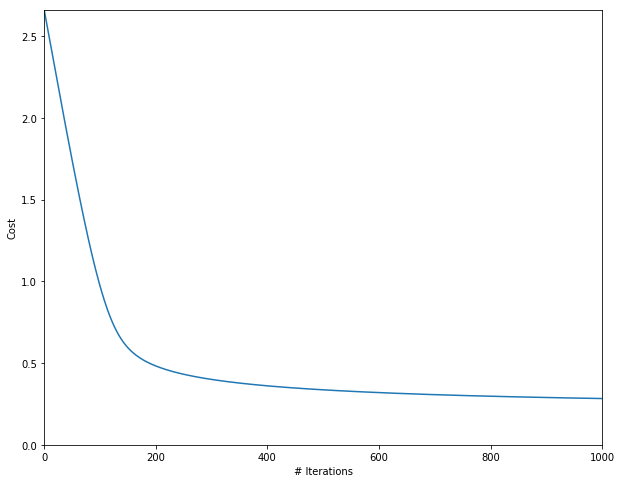
Our accuracy is 86% not too bad with a dataset of only 100 elements. The optimization of the cost function is as follows:
So, our linear regression example looks like follows: